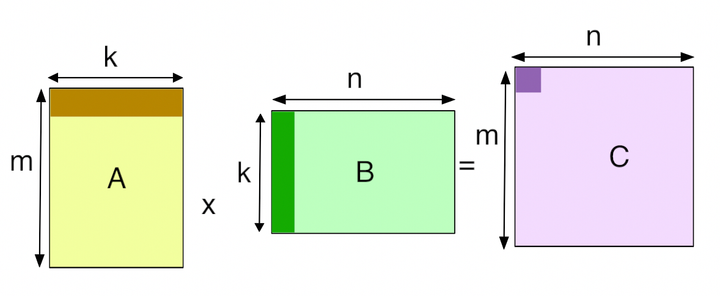
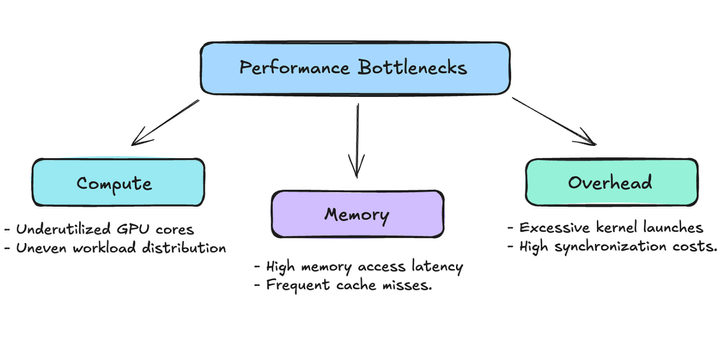
6 Step Optimization of GeMMs in CUDA I aim to take a naive implementation of single-precision (FP32) General Matrix Multiplication (GeMM) and optimize it so its computations can be parallelized effectively on GPUs with CUDA C/C++.
Maximizing Grace Hopper Conference 2025 What to expect and how to prepare for the Biggest Tech Conference for Women!
6 Step Optimization of GeMMs in CUDA I aim to take a naive implementation of single-precision (FP32) General Matrix Multiplication (GeMM) and optimize it so its computations can be parallelized effectively on GPUs with CUDA C/C++.
A Checklist for Your Next SWE Interview How to best prepare for your next software engineering interview–a month before, a week before, a day before!