7 Step Optimization of Parallel Reduction with CUDA
Taking a simple parallel reduction and optimize it in 7 steps.

In this post, I aim to take a simple yet popular algorithm — Parallel Reduction — and optimize its performance as much as possible. This effort is inspired by an NVIDIA webinar hosted by Mark Harris, from which I’m not only recreating the optimizations but also attempting to simplify the concepts for better understanding. Alongside this article, I have provided a GitHub implementation of these methods. While here I only showcase the final kernels with their methods, my GitHub repository includes more detailed information that will assist you in recreating this work.
Let’s get started!
[Sorry there was no better way of showing code through Ghost]
Understanding the Algorithm
Let’s start by exploring what the parallel reduction algorithm entails. It’s a data-parallel primitive that’s straightforward to implement in CUDA. To keep it simple, parallel reduction aims to reduce a vector, matrix, or tensor in parallel by leveraging a GPU’s thread hierarchy. This reduction is achieved through operations like sum(), min(), max(), or avg() to aggregate and reduce the data. We will be using sum() to reduce our dataset. Despite their simplicity, these operations are versatile and crucial for many applications, requiring high optimizations to avoid becoming bottlenecks. Although these computations may seem simple, they can be time-consuming if not efficiently handled.
When parallelizing, the algorithm can be thought of as a tree-based approach, spreading across each thread block of our GPU. A critical question arises: “How can we communicate partial results between thread blocks?” The most straightforward solution might seem to be Global Synchronization — allow each block to compute, then synchronize them all and continue recursively. However, CUDA does not support global synchronization because it is costly in terms of hardware (HW) and would constrain the programmer to using only a few blocks to avoid deadlocks, thus reducing overall efficiency.

A more practical approach to communicating partial results while computing in each thread block is to decompose our kernel into multiple kernels. Kernel decomposition involves breaking down a large kernel task into smaller, manageable sub-tasks, which can be executed independently across different threads or blocks. This method minimizes hardware and software overhead. This allows for more flexible and efficient use of GPU resources, reducing the need for synchronization and improving overall computational speed.

Our Metrics
Our algorithm’s performance hinges on two critical metrics: time and bandwidth. These metrics gauge whether our GPU is being fully utilized, essentially measuring if it’s achieving peak performance. We aim for GPU peak performance with our metrics reflected in terms of compute (GFLOP/s) and memory (GB/s).
To optimize these metrics, we need to focus on two main aspects: data access and computational bottlenecks. This translates to assessing
- how we can make the read and write of data faster, and
- how we can make our computations faster and more efficient. With GPUs, an ideal computation not only fast but also puts most threads to work.
REDUCE-0: Interleaved Addressing
This method serves as our base. A very naive approach to parallelizing reduction is to decide on a pattern for accessing address spaces where our elements are stored, retrieving those elements, combining those elements by summing them, and recursively repeating this process on different threads to parallelize our operation. In fact, this is what we will do for the first 3 methods of optimization.
Interleaved Addressing refers to accessing and combining address spaces that are positioned halfway to the segment that our current thread is dealing with. Consider an array of 1024 integers. If we use 256 threads per block, each thread starts with a different point and skips every 256 elements. For instance, thread 0 would process elements 0, 256, 512, and 768, each time combining its current element with another positioned halfway to the end of the array segment it’s responsible for. So, thread 0 would combine element 0 with element 128, element 256 with 384, element 512 with 640, and element 768 with 896. Then, this would continue recursively until a final result is reached.
This method not only simplifies synchronization among threads but also ensures that all threads are actively reducing data in parallel, leading to a more balanced load and efficient reduction.

// REDUCTION 0 – Interleaved Addressing
__global__ void reduce0(int *g_in_data, int *g_out_data){
extern __shared__ int sdata[]; // stored in the shared memory
// Each thread loading one element from global onto shared memory
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x * blockDim.x + threadIdx.x;
sdata[tid] = g_in_data[i];
__syncthreads();
// Reduction method -- occurs in shared memory because that's where sdata is stored
for(unsigned int s = 1; s < blockDim.x; s *= 2){
if (tid % (2 * s) == 0) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
if (tid == 0){
g_out_data[blockIdx.x] = sdata[0];
}
}
Let’s go through our first implementation step by step:
- Step 1: Assign each thread a starting index based on its thread ID and block size.
- Step 2: Each thread loads its corresponding element from global memory to shared memory.
- Step 3: Synchronize all threads within the block to ensure all data is loaded.
- Step 4: Perform reduction in shared memory; each thread adds or compares its value with the value of another thread at a calculated offset, which halves in each subsequent step because s is doubled each iteration.
- Step 5: Synchronize threads again after each reduction step to ensure data integrity.
- Step 6: The first thread in each block writes the result of the reduction to the output array in global memory. The last call would ensure the final result is written.
Results


Problems with this method
Although this method is a great foundation for parallel programming, it still has its issues. Let’s bring back our metrics and assess where our code might be inefficient in terms of compute and memory.
- Compute: One major computational inefficiency arises from the use of the
%operator, which is computationally expensive because it involves division—a very slow operation at the low-level. This can significantly hamper performance, especially in kernels where this operation is executed frequently across many threads. Additionally, the interleaved addressing pattern leads to highly divergent warps, as threads within the same warp need to execute on different execution paths due to our current ‘if’ condition. This divergence in paths causes the warps to stall, waiting for other threads to catch up, which severely degrades performance. - Memory: Consequently, with divergent warps, memory access patterns in this method are suboptimal. Since each thread accesses data elements spread across the entire array, the memory accesses are scattered and not coalesced, leading to inefficient use of the memory bandwidth and higher latency in data retrieval. This scattered access pattern can cause multiple, slow memory transactions instead of a single, fast transaction, thus not fully utilizing the GPU’s memory bandwidth capabilities. However, we start solve this problem a bit later.
First, let’s focus on compute-related problems with our next optimization.
REDUCE-1 : Interleaved Addressing 2.0
This method doesn’t change much from our previous method. The addressing is the same, but this time we construct our reduction function without the use of % operator or the divergent condition. By restructuring the index calculation (int index = 2 * s * tid;), REDUCE-1 ensures that each thread consistently performs its operation without checking the position relative to its stride, thereby removing divergence within the warp. This adjustment means all threads in a warp follow the same execution path, significantly improving the warp efficiency. The removal of the % operator further enhances performance by avoiding costly modulo operations, which are slow on GPUs due to their reliance on division.
// REDUCTION 1 – Interleaved Addressing without branch divergence and % operation
__global__ void reduce1(int *g_in_data, int *g_out_data){
extern __shared__ int sdata[]; // stored in the shared memory
// Each thread loading one element from global onto shared memory
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x * blockDim.x + threadIdx.x;
sdata[tid] = g_in_data[i];
__syncthreads();
// Reduction method -- occurs in shared memory
for(unsigned int s = 1; s < blockDim.x; s *= 2){
// note the stride as s *= 2 : this causes the interleaving addressing
int index = 2 * s * tid; // now we don't need a diverging branch from the if condition
if (index + s < blockDim.x)
{
sdata[index] += sdata[index + s]; // s is used to denote the offset that will be combined
}
__syncthreads();
}
if (tid == 0){
g_out_data[blockIdx.x] = sdata[0];
}
}
Results
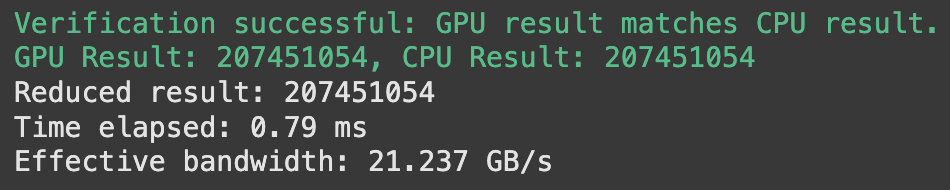

Problems with this method
While REDUCE-1 improves on the computational efficiency and execution coherence over REDUCE-0, it introduces a new problem: shared memory bank conflicts. These conflicts occur when multiple threads attempt to access data from the same memory bank simultaneously. These bank conflicts lead to serialization of what could otherwise be parallel memory accesses.
From REDUCE-0 to REDUCE-1, we increased the computational efficiency of our algorithm. However, we did not solve the memory-related issues. In fact, we caused more memory-related issues by switching to strides. It is a bit hard to visualize, but essentially the stride method causes the threads to try and access the same shared memory addresses. REDUCE-0 spread out threads in intervals that acted like “boundaries” and kept thread accesses within those boundaries, reducing the chances of conflicts. But REDUCE-1 relies on strides and removes these boundaries, causing bank conflicts and serialization of processes.
Each bank can only service one access per cycle, so when multiple accesses are directed to the same bank, they must be serialized, effectively reducing the throughput of memory operations. This serialization negates some of the performance gains achieved by eliminating warp divergence and can become a significant bottleneck, especially in larger blocks where the probability of bank conflicts increases. Let’s try to solve this problem now.
REDUCE-2: Sequential Addressing
This method employs a different addressing technique that is more efficient. Instead of threads accessing elements spaced widely apart (interleaved addressing), this method employs sequential addressing where each thread deals with consecutive elements.
Let’s break that down. Bringing back our 1024 element example with 256 threads per block, thread 0 would try and access elements 0, 1, 2, 3 instead of 0, 256, 512, 768 which are spaced far apart. Thread 0 combines elements 0 and 1, then element 2, and so on recursively. What this does is take advantage of spatial locality and avoids bank conflicts by being cache efficient. The algorithm is also linear and minimizes the need for synchronization that increases wait times.
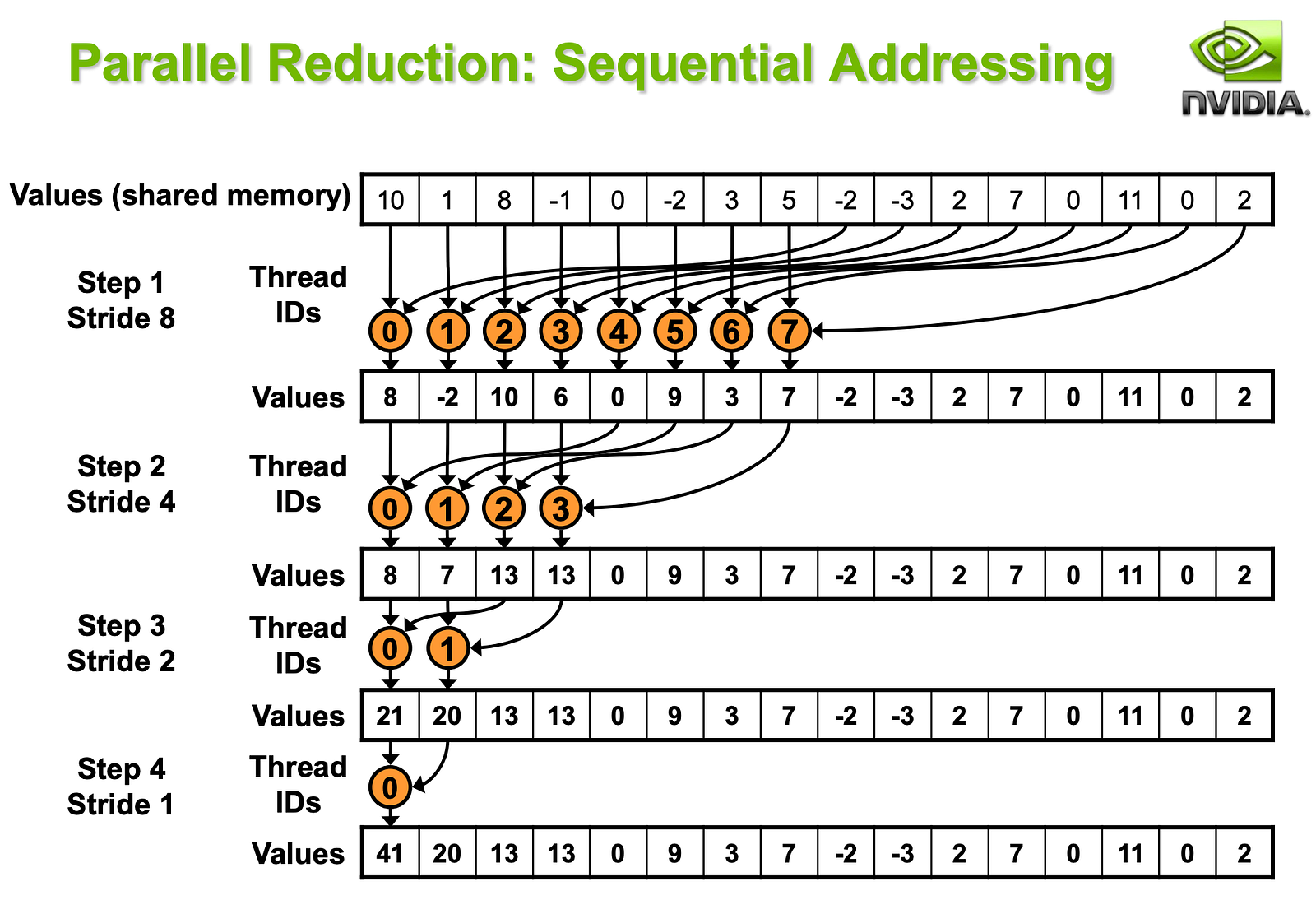
This change significantly enhances memory access patterns by aligning them more closely with the GPU’s preference for coalesced memory accesses. By accessing adjacent memory locations, REDUCE-2 reduces the likelihood of cache misses and memory bank conflicts, making the memory bandwidth usage more efficient and improving overall performance of the reduction operation.
// REDUCTION 2 – Sequence Addressing
__global__ void reduce2(int *g_in_data, int *g_out_data){
extern __shared__ int sdata[]; // stored in the shared memory
// Each thread loading one element from global onto shared memory
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x * blockDim.x + threadIdx.x;
sdata[tid] = g_in_data[i];
__syncthreads();
// Reduction method – occurs in shared memory
for(unsigned int s = blockDim.x/2; s > 0; s >>= 1){
// REDUCE2 -- check out the reverse loop above
if (tid < s){ // then, we check threadID to do our computation
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
if (tid == 0){
g_out_data[blockIdx.x] = sdata[0];
}
}
Let’s dive into the algorithm a bit. The major changes in this method include the replacement of strided indexing with a reversed loop structure coupled with threadID-based indexing. This fundamentally modifies how data is handled during reduction.
- Reversed Loop: We start the reduction with the highest possible stride with
s = blockDim.x / 2and reduce it in each iteration by half. This means the threads first handle the widest gaps between the data they are summing, which quickly reduces the overall amount of data being processed. - threadID-based indexing: Each thread uses its ID to access consecutive pairs of data points, rather than scattered ones, streamlining the access pattern and minimizing memory latency. As
sdecreases, threads combine adjacent elements, optimizing memory use and enhancing data throughput.
Results


Problems with this method
This method is mostly conflict free. At this point, we have employed obvious changes to resolve compute and memory issues. We should now try to make our algorithm smarter and find ways to construct it so we can make it faster.
One major problem is that half of the threads are idle in the first loop iteration which is wasteful and underutilizes our GPU’s compute. Although this was the case in our previous techniques, we had bigger fish to fry before getting to idle threads. Going with our 1024 element example, in the first iteration of the loop where s=blockDim.x/2, or s=512 in this case, the condition if (tid < s) restricts active computation to only the first 512 threads of the block. This condition means that while these 512 threads are actively summing pairs of elements (for example, sdata[tid] with sdata[tid + 512]), the remaining 512 threads are idle, contributing nothing to the computation. This pattern of halving the number of active threads in each subsequent iteration continues until the reduction completes; from 512, to 256, then 128, 64, 32 and so on. This rapid halving leads to a significant underutilization of the GPU's capabilities, especially in the initial iterations where only a fraction of the available threads are used.
Let’s solve this problem by doing our first computations when we load our data onto shared memory.
REDUCE-3: First Add During Load
To make use of our idle threads and make our computation smarter, we will do our first computation while we are loading our elements from global memory to shared memory. This will help us load and reduce two elements to one and halve the number of blocks we need to deal with.
More concretely put, in our array of 1024 elements with 256 threads, each thread would load the sum of their first two elements onto shared memory (e.g., thread 0 processes elements 0 and 1, thread 1 processes elements 2 and 3, and so forth). Meaning, that we would halve the number of blocks and the length of our shared memory — in this example, to 512. The rest of the code works exactly as it did before in REDUCE-2. This means that our first iteration would still activate 512 threads to start reducing our elements because of s=blockDim.x/2 = 512. Evidently, this would put more threads to work and avoid any slackers!
// REDUCTION 3 – First Add During Load
__global__ void reduce3(int *g_in_data, int *g_out_data){
extern __shared__ int sdata[]; // stored in the shared memory
// Each thread loading one element from global onto shared memory
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockDim.x*2) + threadIdx.x;
sdata[tid] = g_in_data[i] + g_in_data[i+blockDim.x];
__syncthreads();
// Reduction method -- occurs in shared memory
for(unsigned int s = blockDim.x/2; s > 0; s >>= 1){
// check out the reverse loop above
if (tid < s){ // then, we check tid to do our computation
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
if (tid == 0){
g_out_data[blockIdx.x] = sdata[0];
}
}
During implementation, we see this method unveil as three major changes to our prior code (changes highlighted in bold). We first do our initial reduction step while loading the elements from global memory to shared memory: sdata[tid] = g_in_data[i] + g_in_data[i+blockDim.x] . Then, we make a two changes to accommodate this change:
- change the computation of
ito beunsigned int i = blockId.x * (blockDim.x*2) + threadId.xbecause each thread now handles two inputs at once, doubling the effective index range that each block covers. - In our main function, we also change how we call this kernel by set its execution configuration for
num_blocksto beint num_blocks = (n + (2*blockSize) — 1 / (2*blockSize). This assigns half the number of blocks (num_blocks) that are allocated to the kernel and maintains the accuracy of the code.
Result


Problems with this method
Our current approach works great! But, can we make it faster and smarter? Let’s check in with our two metrics. With around 41 GB/s bandwidth usage on Tesla T4, we are definitely not reaching or exhausting our bandwidth. On the other hand, reduction has low arithmetic intensity, meaning we are not compute bound either.
Introducing our new villain…
Because we are not bandwidth bound or compute bound, there is one more bottleneck we can still check for: Instruction Overhead. This includes all the operations, or ancillary instructions, the GPU performs that are not directly related to loading data, storing data, or executing the primary arithmetic operations of the reduction. In other words, these include address arithmetic (calculating with address space to load next) and loop overhead (handling loops, loop conditions, and loop iterations).
Our strategy for this bottleneck would be Loop Unrolling.
REDUCE-4: Unroll Last Warp
Let’s discuss what’s happening in REDUCE-3 first to understand the need for this. With 1024 elements example, After the initial loading where each thread loads and adds pairs of elements, 256 threads work on 512 elements. Here, the reduction begins with each thread working on single elements moving forward. This means,
- when
s = 256we have 256 active threads - when
s = 128we have 128 active threads - when
s = 64we have 64 active threads - when
s = 32we have 32 active threads : At this point, with instructions being SIMD synchronous within a warp, it means two things. First, we don’t need__syncthreads()because all threads work in one lockstep. And second, we don’t needif (tid < s)because each thread needs to work anyways regardless of that condition. Thus, we can safely remove all synchronization commands from this segment of the code, significantly boosting the speed of the final reductions.
// Adding this function to help with unrolling
__device__ void warpReduce(volatile int* sdata, int tid){
// the aim is to save all the warps from useless work
sdata[tid] += sdata[tid + 32];
sdata[tid] += sdata[tid + 16];
sdata[tid] += sdata[tid + 8];
sdata[tid] += sdata[tid + 4];
sdata[tid] += sdata[tid + 2];
sdata[tid] += sdata[tid + 1];
}
// REDUCTION 4 – Unroll Last Warp
__global__ void reduce4(int *g_in_data, int *g_out_data){
extern __shared__ int sdata[]; // stored in the shared memory
// Each thread loading one element from global onto shared memory
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockDim.x*2) + threadIdx.x;
sdata[tid] = g_in_data[i] + g_in_data[i+blockDim.x];
__syncthreads();
// only changing the end limit to stop before s = 32
for(unsigned int s = blockDim.x/2; s > 32; s >>= 1){
// check out the reverse loop above
if (tid < s){ // then, we check tid to do our computation
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
// Adding this to use warpReduce when s = 32
if (tid < 32){
warpReduce(sdata, tid);
}
if (tid == 0){
g_out_data[blockIdx.x] = sdata[0];
}
}
The implementation is straightforward enough. We stop our loop before s = 32 and call the kernel warpReduce, with our handwritten 6 iterations, that runs only on __device__. We also need to use the keyword volatile in order for our implementation to still be correct.
Result

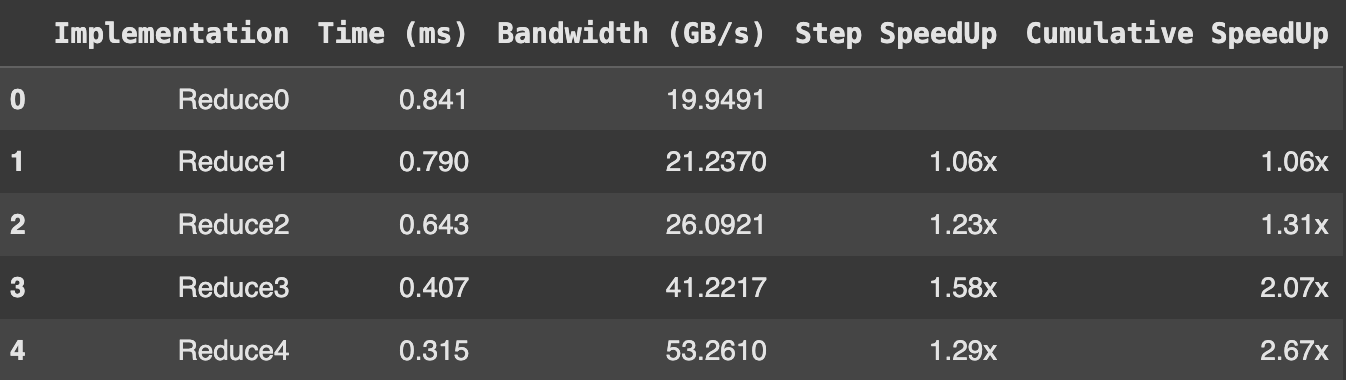
Problems with this method
There are definitely no problems with this; we’re getting great speedup! But, why stop our unrolling journey here when we have so many more loops to unroll!!
REDUCE-5: Completely Unroll
In order to continue our unrolling, we would need to know the total number of iterations of our loops at compile time. Luckily for us, the block size is limited to 512 threads by the GPU and we tend to stick to power-of-2 blocks. We know that we can easily unroll for a fixed block size, we just need to be generic. To help with this CUDA supports and provides C++ template parameters in device and host functions.
Templates in C++ allow us to write flexible, generic programs by letting us define functions or classes with placeholders that can be later substituted with specific types provided at compile time. We use this to make account for the potential variations in blockSize that would change unrolling requirements. Depending on the block size, different switch cases are prepared to handle the specific unrolling requirements. This complete unrolling eliminates unnecessary loops and conditions for the majority of the reduction phases, minimizing computational overhead.
By compiling different versions of the kernel tailored to specific block sizes (such as 512, 256, and 128), we optimize each variant for its particular scenario, stripping away any unnecessary operations and maximizing both memory and compute resource efficiency. In this specific implementation, I’ve chosen to set the blockSize to 256 in the main function, simplifying our approach. However, I’ve included switch cases for block sizes of 512, 256, and 128 to demonstrate this method’s flexibility and to highlight how effectively CUDA can leverage template parameters to enhance performance across different configurations.
// Adding this function to help with unrolling and adding the Template
template <unsigned int blockSize>
__device__ void warpReduce(volatile int* sdata, int tid){
if(blockSize >= 64) sdata[tid] += sdata[tid + 32];
if(blockSize >= 32) sdata[tid] += sdata[tid + 16];
if(blockSize >= 16) sdata[tid] += sdata[tid + 8];
if(blockSize >= 8) sdata[tid] += sdata[tid + 4];
if(blockSize >= 4) sdata[tid] += sdata[tid + 2];
if(blockSize >= 2) sdata[tid] += sdata[tid + 1];
}
// REDUCTION 5 – Completely Unroll
template <unsigned int blockSize>
__global__ void reduce5(int *g_in_data, int *g_out_data){
extern __shared__ int sdata[]; // stored in the shared memory
// Each thread loading one element from global onto shared memory
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockDim.x*2) + threadIdx.x;
sdata[tid] = g_in_data[i] + g_in_data[i+blockDim.x];
__syncthreads();
// Perform reductions in steps, reducing thread synchronization
if (blockSize >= 512) {
if (tid < 256) { sdata[tid] += sdata[tid + 256]; } __syncthreads();
}
if (blockSize >= 256) {
if (tid < 128) { sdata[tid] += sdata[tid + 128]; } __syncthreads();
}
if (blockSize >= 128) {
if (tid < 64) { sdata[tid] += sdata[tid + 64]; } __syncthreads();
}
if (tid < 32) warpReduce<blockSize>(sdata, tid);
if (tid == 0){
g_out_data[blockIdx.x] = sdata[0];
}
}
Also, we should change the way our kernel is called to implement unrolling:
// Needed for Complete unrolling
// Launch Kernel and Synchronize threads
switch (blockSize) {
case 512:
reduce6<512><<<num_blocks, 512, 512 * sizeof(int)>>>(dev_input_data, dev_output_data, n);
break;
case 256:
reduce6<256><<<num_blocks, 256, 256 * sizeof(int)>>>(dev_input_data, dev_output_data, n);
break;
case 128:
reduce6<128><<<num_blocks, 128, 128 * sizeof(int)>>>(dev_input_data, dev_output_data, n);
break;
}
The implementation doesn’t change much from REDUCE-4; we simply try to now feed in blockSize as a template parameter that is determined at compile time. Like before, we include if statements to tend to different values of blockSize and switch statements to call kernels based on those values.
Result

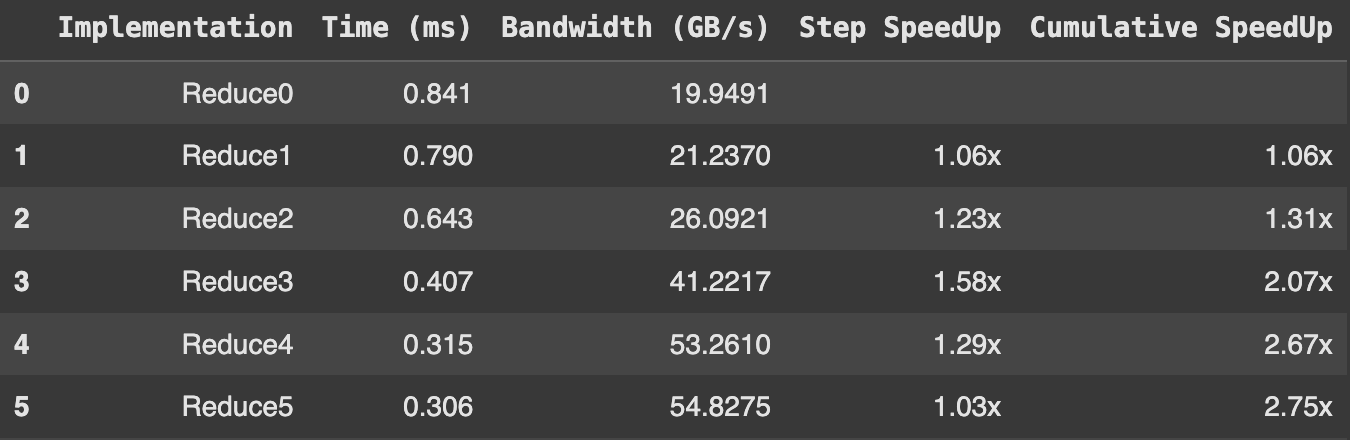
Problems with this method
While Reduce5 enhances efficiency by fully unrolling loops for known block sizes, we can’t use this method flexibly and scale it up. Specifically, the full unrolling technique relies heavily on compile-time optimizations that restrict the kernel to fixed block sizes. This approach can lead to inefficiencies in scenarios where the data size does not perfectly match the block configurations, potentially underutilizing GPU resources. Additionally, the complexity of managing multiple versions of the kernel for each block size increases the development overhead and limits dynamic adaptability to varying workloads, making it less practical for general-purpose applications where input sizes can vary greatly.
So, let’s try to get inspiration from First-Add-During-Load from REDUCE-3 and try to do as many Adds as possible instead of just the first one.
REDUCE-6: Multiple Adds / Threads
Transitioning to Reduce6 addresses the rigidity and scalability issues seen in Reduce5 by introducing a more dynamic approach termed “algorithm cascading”. In this method, each thread performs multiple additions within a broader range of block sizes, effectively reducing the dependency on specific block configurations. This flexibility allows the algorithm to adapt more fluidly to varying data sizes, optimizing resource utilization across a wider array of scenarios. By combining both sequential and parallel reductions, Reduce6 minimizes latency and maximizes throughput, particularly in environments with high kernel launch overheads and diverse workload sizes. The strategic distribution of work across threads, as per Brent’s theorem, ensures that each thread contributes optimally throughout the reduction process, maintaining cost-efficiency while scaling effectively with the hardware capabilities.
For example, rather than each thread processing a single pair of elements, it might process multiple pairs before any synchronization barrier, thereby amortizing the cost of synchronization across more computation and improving the overall performance.
Final Optimized Kernel
// Adding this function to help with unrolling and adding the Template
template <unsigned int blockSize>
__device__ void warpReduce(volatile int* sdata, unsigned int tid){
if(blockSize >= 64) sdata[tid] += sdata[tid + 32];
if(blockSize >= 32) sdata[tid] += sdata[tid + 16];
if(blockSize >= 16) sdata[tid] += sdata[tid + 8];
if(blockSize >= 8) sdata[tid] += sdata[tid + 4];
if(blockSize >= 4) sdata[tid] += sdata[tid + 2];
if(blockSize >= 2) sdata[tid] += sdata[tid + 1];
}
// REDUCTION 6 – Multiple Adds / Threads
template <int blockSize>
__global__ void reduce6(int *g_in_data, int *g_out_data, unsigned int n){
extern __shared__ int sdata[]; // stored in the shared memory
// Each thread loading one element from global onto shared memory
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockSize*2) + tid;
unsigned int gridSize = blockDim.x * 2 * gridDim.x;
sdata[tid] = 0;
while(i < n) {
sdata[tid] += g_in_data[i] + g_in_data[i + blockSize];
i += gridSize;
}
__syncthreads();
// Perform reductions in steps, reducing thread synchronization
if (blockSize >= 512) {
if (tid < 256) { sdata[tid] += sdata[tid + 256]; } __syncthreads();
}
if (blockSize >= 256) {
if (tid < 128) { sdata[tid] += sdata[tid + 128]; } __syncthreads();
}
if (blockSize >= 128) {
if (tid < 64) { sdata[tid] += sdata[tid + 64]; } __syncthreads();
}
if (tid < 32) warpReduce<blockSize>(sdata, tid);
if (tid == 0){
g_out_data[blockIdx.x] = sdata[0];
}
}
Peep the while loop where each thread performs multiple additions directly in shared memory. This loop is designed to aggregate two data elements per thread for each iteration, effectively halving the number of necessary operations and interactions with global memory. The thread loads data from the global memory, adds it to a previously loaded value, and then jumps forward by the total number of threads times two, ensuring that it processes another pair of elements on the next iteration. This pattern significantly reduces the total amount of data each thread needs to handle at any one time, maximizing the use of available bandwidth and minimizing latency.
FINAL RESULTS


Comparing it with NVIDIA’s Performance metrics

One of the main differences between my implementation and NVIDIA’s is in GPU. For the webinar, they use GeForce 8800, while I used Tesla T4. This made my initial implementation a lot better right away than theirs, because of a more optimized architecture. However, it also left very little space for improvement in speedup. While I am not able to match the dramatic speedups, I am able to showcase continuous optimization and increasing GPU peak performance.
Generalizing Optimization Techniques
I’m simply going to list down my key takeaways while optimizing a CUDA kernel:
- Understanding Core Performance Characteristics is key: memory coalescing, managing divergent branching, resolving bank conflicts, and employing latency hiding techniques.
- Utilize Performance Metrics: use compute and memory performance metrics to identify whether the kernel is compute-bound or memory-bound.
- How to Identify Bottlenecks: Determine if the kernel’s limitations are due to memory, computation, or instruction overhead.
- Algorithm Optimization: Refine and then unroll the algorithm to enhance performance.
- Leverage Template Parameters: Use template parameters to fine-tune code generation, ensuring optimal configuration for varying block sizes.
I hope this was helpful!
Source: https://developer.download.nvidia.com/assets/cuda/files/reduction.pdf
My GitHub Implementation: https://github.com/rimikadhara67/Parallel-Reduction?tab=readme-ov-file