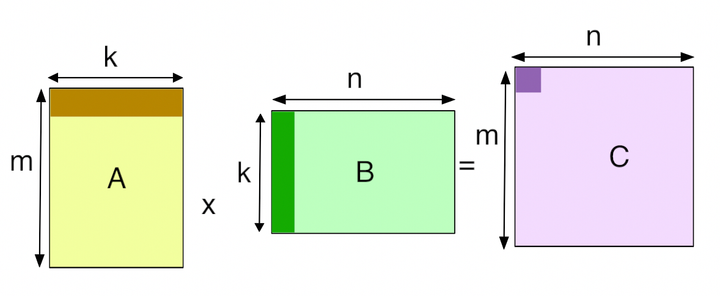
6 Step Optimization of GeMMs in CUDA I aim to take a naive implementation of single-precision (FP32) General Matrix Multiplication (GeMM) and optimize it so its computations can be parallelized effectively on GPUs with CUDA C/C++.
Low-Precision Arithmetic in ML Systems Have you ever wondered how modern AI systems handle billions of calculations without melting your computer? The secret sauce lies in something called low-precision arithmetic. Let’s dive into what this means and why it matters.
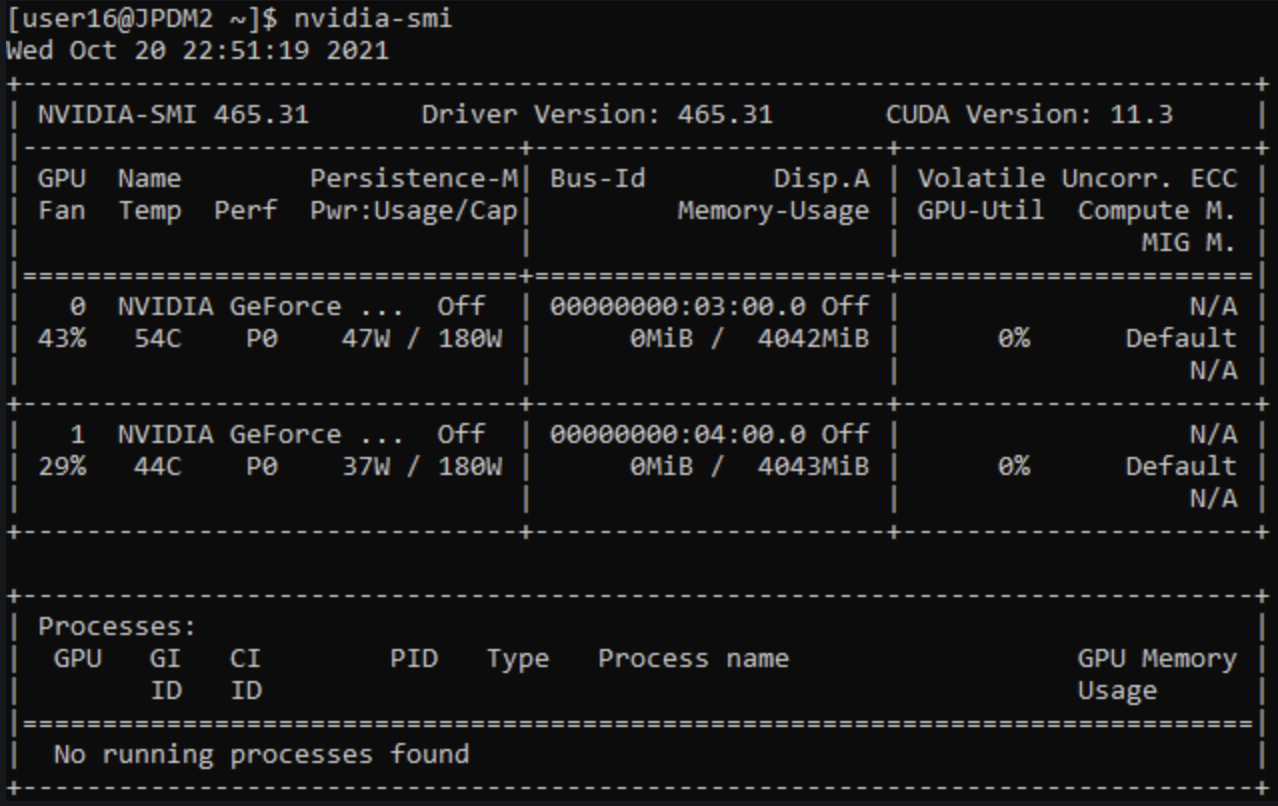
CUDA 4: Profiling CUDA Kernels Some tools, metrics, and techniques for CUDA kernel profiling, making the optimization process more systematic and approachable.
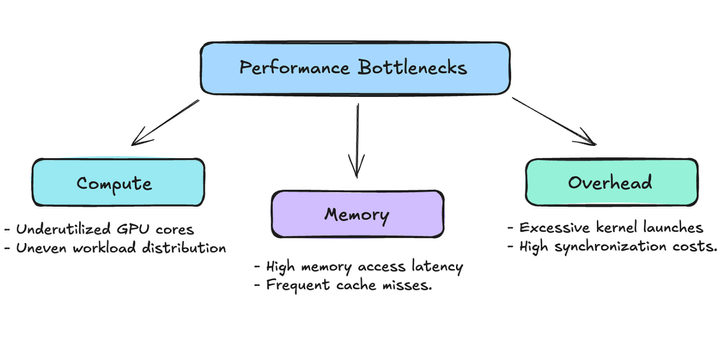
CUDA 3: Your Checklist for Optimizing CUDA Kernels How to optimize CUDA kernels and how we can build intuition behind kernel optimizations.
7 Step Optimization of Parallel Reduction with CUDA Taking a simple parallel reduction and optimize it in 7 steps.