CUDA 0: From OS to GPUs
Let's get started with CUDA and learn the basics of Parallel Programming

This is the first of many articles I plan on writing on Mastering CUDA.
With this article, I hope to provide a gentle and digestible bridge between what you might know from your CS class on Operating Systems and help you understand the power of Parallel Programming with CUDA. In this article, I’ll lay out the ground work with some review of familiar concepts, a brief history about the need for scaling up, and solidifying your understanding about how a computer works. This article is meant to be less technical and more conceptual.
Let’s get started!
For this series, I’ll be assuming that you are familiar with basic C/C++ and Operating Systems. I’ll also assume that you are familiar with the usage of GPUs for Parallel Programming, although I’ll rehash a lot of it here.
Here’s the Outline for this article:
- Introduction: Key definitions, Motivation behind Parallelism
- Important Concepts in Parallel Programming
- Understanding Computer Reads and Writes with an Example
Introduction and Overview
Key Definitions
Before we dive deeper into the world of CUDA and GPU programming, it’s essential to refresh some key terms that you may have encountered in your computer architecture or operating systems classes. Here’s a quick recap to ensure we’re all starting from the same foundation.
- Threads: The smallest sequence of programmed instructions that can be managed independently by a scheduler.
- Processes: An instance of a computer program that contains its code and its own memory space. Processes are more heavyweight than threads and are used to execute one or more threads within them.
- Latency: The time taken to complete a specific task or the delay between the initiation and the execution of an operation.
- Throughput: The amount of work done in a given period of time.
- Clock Speed: The speed at which a processor executes instructions, measured in cycles per second or hertz. Higher clock speeds can translate to faster processing times, though they also lead to greater heat generation.
- Cores: They have slightly different definitions for CPUs v/s GPUs. But overall, cores refer to the processor units that reads and executes program instructions.
- Compute: Refers to the actual processing power or the computational capabilities. This involves executing program code through arithmetic and logical operations.
- Memory: The data storage that can be accessed directly by the processor.
- Bandwidth: The maximum rate at which data can be transferred over a network or between components in a computer.
- Caching System: A component that stores temporary data in computing environments to reduce the time to access frequently used data.
- Synchronization: The process of trying to align multiple systems or data streams in order to ensure consistency and coordination in real-time or near-real-time.
These terms will be given more context from the perspective of GPUs and CUDA C/C++ Programming as we go further. I just wanted us all to get warmed up.
What is Performance?
In the realm of computing, performance hinges on three key factors — latency (speed of task completion), throughput (amount of processed tasks), and resource utilization (putting all resources to work). In an ideal world, we would have processors that can process tasks in parallel (max throughput) while completing those tasks in no time (max latency) and utilize all the cores that are assigned to them. But, in reality, that is not possible and there is an obvious tradeoff between latency and throughput.
We will discuss the metrics for performance and the ways to optimize our computations in later chapters. But for now, it is important to recognize that as computational demands continue to increase, optimizing performance ensures that systems can meet modern requirements without excessive energy consumption or hardware costs. Which is why CPU’s just weren’t enough for us.
Why CPUs just weren’t enough
As many of us might know, around 2004–2005, the world of CPU architecture and CPU performance hit two walls — Power wall and Memory Wall.
- Power Wall: More computational/processing speed requires more power which requires higher voltage for compute stability. This got increasingly difficult to produce due to higher cost and greater heat generation that restricter microprocessor design.
- Memory Wall: Increased computations also required increased data access which means increased communication between memory units and processing units which leads to higher latency.
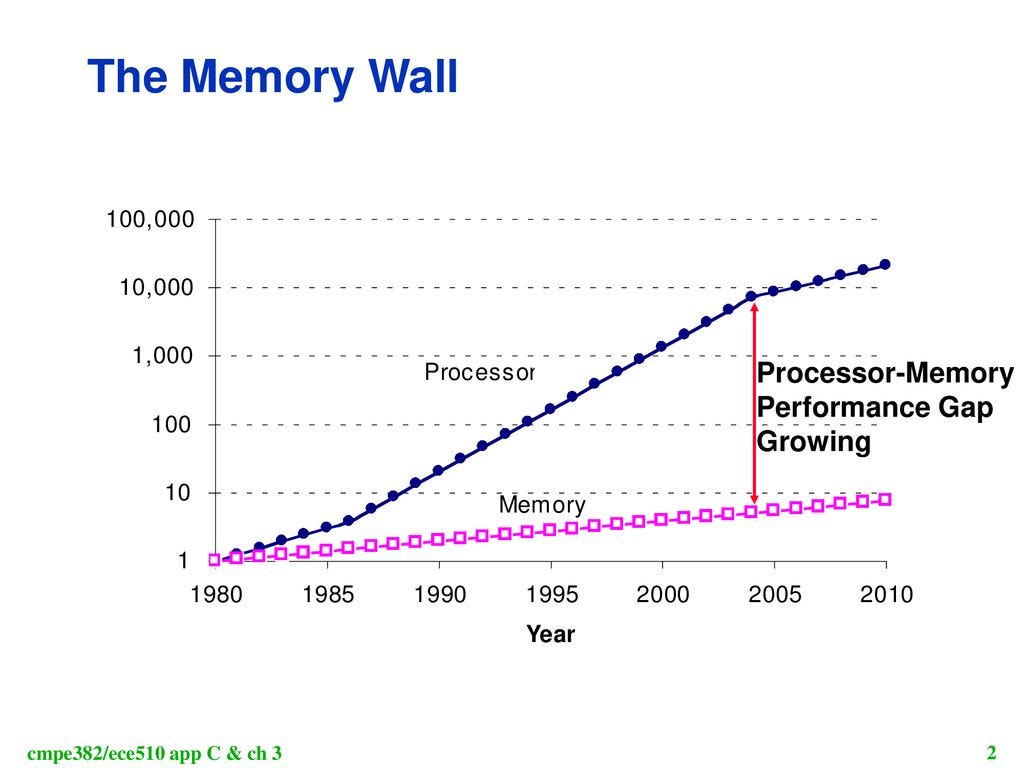
These two issues gave birth to Parallel Programming. Initially, this meant multi-core processors in CPUs for computations, but even these solutions have their limitations — particularly in terms of how many cores can be effectively utilized in a single CPU due to physical and cost constraints. The advent of multi-core CPUs did help a lot by allowing multiple tasks to be processed simultaneously, thus improving performance over single-core CPUs. However, the inherent sequential nature of traditional CPU architecture still posed significant challenges for truly scalable parallel execution.
What are CPUs good for?
CPUs are extremely efficient in handling and decreasing latency for a particular process. They work on low-latency principle and are known for two highly optimized parts: Caching System and Control Unit. CPUs have sophisticated cache architectures and control units capable of handling a wide variety of tasks effectively. They can quickly switch between tasks, manage multiple operations based on priority, and handle high-level computations that require a deeper understanding of the data context or the specific needs of the software.
However, CPUs are highly inefficient when measuring throughput and where there is the need for parallelism. While multi-core CPUs can execute several threads in parallel, each core is essentially a separate CPU, and the cores do not scale linearly due to overhead in coordination and data exchange. This limits the performance gains from simply adding more cores. We’ll look at CPUs more thoroughly in the next article.
Introducing GPUs!!
To overcome these limitations, particularly for applications that benefit from massive parallelism, GPUs (Graphics Processing Units) have become increasingly popular. Originally designed for handling graphics and video rendering, GPUs are built around a highly parallel structure that can handle thousands of threads simultaneously.
GPUs enable this by prioritizing throughput in order to hide latencies that occurs during communication and data access. It is architecturally set up to process as many independent instructions as possible at once so it relies less on communication between cores and more on the individual computations within the cores. For tasks that are less dependent on branching and more on the sheer volume of arithmetic computations, such as image processing or deep learning, GPUs drastically reduce computation time. Their architecture allows them to excel in throughput-oriented tasks where the same operation is performed on many data points simultaneously.
We’ll look at GPUs more thoroughly in the next article .In order to continue understanding CPUs and GPUs in our next chapter, it is important for us to understand our computer’s data access patterns and principles.
Understanding How a Computer Reads and Writes
Imagine you’re playing a game where your group must complete 100 tasks, of different difficulties, given in 100 envelopes to advance to the next level. Your group includes you and four other members, making a total of five players. Each task, numbered from 1 to 100, needs to be completed as quickly as possible to win. However, you must work under three specific constraints:
- One person can read instructions for only one task at a time.
- The next person cannot receive their task envelope(s) until the person before them is on their last envelope.
- Each task must be read at the original spot (where they received the instructions) and it must be completed at a different location from the original location.
To organize the task completion efficiently under these constraints, you could employ two different strategies:
Method 1: Assign each member a set of 20 tasks one after the other. For example, the first member takes tasks 1–20, the second takes 21–40, and so on. Each member reads their task envelopes one at a time, then moves to the specific locations to execute those tasks. However, in this method, they cannot do it all at once because of the second rule. So the second person has to wait for the first person to open their last envelope in order to receive their set of 20. You can imagine how long the fifth person has to wait before they can be of any use to the group! Clearly this is inefficient, especially when the all tasks and information are independent of each other.
Method 2: The five members receive only one envelope at a time and once their task is done, they line up behind the last person in the queue. After the first person is off to their location for their task, the second person can immediately receive instructions for their task since the first person only has one envelope in their hand that has ben read. This cycle repeats until all tasks are completed. This method keeps each member constantly active, but they spend a lot of time traveling between the instruction point and task locations.
Analysis of this Example
Although this analogy isn’t perfect, it depicts some major constraints and workings of how our computers receive instructions and process data.
Needless to say, Method 2 is superior to the first method and should be employed to win. This analogy serves to illustrate key points about how computers handle data processing and computation:
- Wait Times and Task Dependency: Method 1 illustrates the inefficiencies inherent in sequential processing and dependency. Much like a single-threaded system, this method forces each member to wait for the one ahead to reach a certain point before they can proceed, creating bottlenecks that significantly delay the overall task completion. Method 2 reduces wait times and mimics a multi-threaded system where different threads (or members) can operate independently as soon as they have the instructions they need. This not only speeds up the process but also ensures that no resources are left idle unnecessarily.
- Data Transfer and Location: The requirement for tasks to be completed at a location different from where the instructions are received can be likened to the way a computer system handles operations between the CPU and memory. Just as the members must travel back and forth between the instruction point and the task locations, in computing, data must often be transferred between different storage locations and the CPU for processing. This requirement, while necessary, introduces latencies that can impact performance, especially if the data transfer mechanisms are not optimized.
- Efficiency and Task Management: Method 2 offers a more dynamic and flexible approach, allowing for adjustments based on immediate circumstances, much like how an operating system manages CPU scheduling. Tasks can be allocated and handled as needed without waiting for a complete batch to be processed, which optimizes the use of available resources.
- Scalability and Resource Utilization: The second method demonstrates better scalability and resource utilization, analogous to how GPUs handle computations. In GPU architecture, multiple processors can work on different parts of a problem simultaneously, which is similar to having multiple members working independently on separate tasks as soon as they receive the go-ahead. This parallelism is crucial for handling large volumes of operations, such as in graphics rendering or large-scale simulations.
Conclusion
I hope this article helped build your intuition behind Parallel Programming and the need for GPUs in spite of CPUs. For my next article, we’ll go much more in depth about how GPUs are architecturally and logically different from CPUs and the introduce some key concepts behind Parallel Computing. For future articles, I plan on showcasing how to get started with CUDA, build a Neural Network from scratch in CUDA, how to profile it and how to optimize CUDA kernels. So stay tuned!
Please stay tuned for my next posts about CUDA!
Resources
- https://csl.cs.ucf.edu/courses/CDA6938/s08/G80_CUDA.pdf
- https://github.com/CisMine/Parallel-Computing-Cuda-C/
- https://towardsdatascience.com/cuda-for-ai-intuitively-and-exhaustively-explained-6ba6cb4406c5
- https://web.archive.org/web/20231002022529/https://luniak.io/cuda-neural-network-implementation-part-1/
- https://developer.nvidia.com/blog/even-easier-introduction-cuda/
- https://www.nvidia.com/en-us/on-demand/session/gtc24-s62191/
- https://csl.cs.ucf.edu/courses/CDA6938/s08/G80_CUDA.pdf