Simplify Reinforcement Learning Models (Conceptually)
A beginner-friendly guide to understanding key concepts and strategies in Reinforcement Learning, revealing how they seamlessly come together.

Content Overview:
- Basics of Reinforcement Learning — Intuition and Key Terms
- Policies in Reinforcement Learning
- Learning Strategies in Reinforcement Learning
- Different Exploration Strategies
- Reward Functions
- How These Concepts Come Together

Basic Intuition + Key Terms
Reinforcement Learning (RL) is like raising and introducing a child to the new world. It is a fascinating area of machine learning that focuses on training agents (our child) to help them make sequences of decisions in an environment (their new world). By interacting with an environment, the agent learns to achieve a goal through trial and error, receiving rewards or penalties along the way. Reinforcement Learning is one of the more intuitive ML techniques, in my opinion, because it is very close to how our brains learn and adapt to our environment. In RL, we aim to mimic how humans improve their performance over time. While people might not excel at a task on their first attempt, repeated exposure to the environment allows them to refine their decision-making process, ultimately optimizing their actions to achieve the best possible outcomes.
Understanding the different aspects and techniques within RL is crucial for designing effective RL models. This article will break down the key components/definitions of RL in an approachable way, helping you grasp the concepts without getting bogged down in complex math.
At its core, RL involves an agent that interacts with an environment. The agent takes actions based on its current state, and the environment responds with the next state and a reward. Key components include:
- Agent: The learner or decision-maker.
- Environment: The external system the agent interacts with.
- State: A representation of the current situation of the agent.
- Action: A decision made by the agent.
- Reward: Feedback from the environment to evaluate the action.
This process where the agent is learning is like a loop — the agent starts with an action that changed the state of the environment and reaps some rewards (reinforcement) which prompts the agent to take the next action. But, obviously our goal is not to keep looping endlessly, it is for the agent to learn to take the best set of actions in every state.
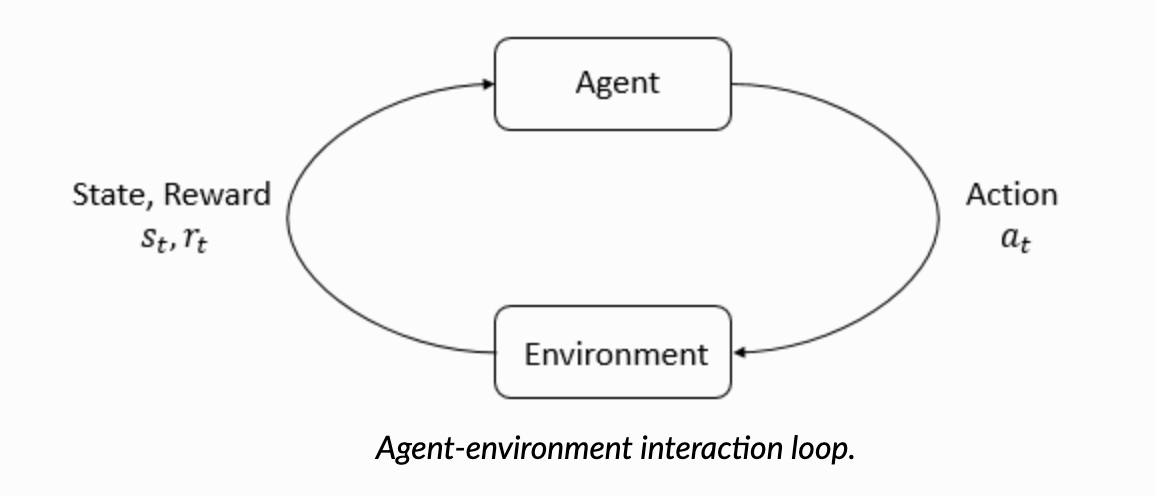
Our goal, in most cases, is to maximize the reward received by the agent through its actions in various states within the environment.
But, that is our end goal. First, we need to train our child, our agent. RL is an unsupervised machine learning technique, meaning it doesn’t rely on pre-labeled data. Instead, it learns from trial and error, much like how a child learns about the world. A child isn’t born with a vast amount of information; rather, they learn by living and experiencing their environment firsthand.
Similarly, our agent explores its environment and collects its own data through episodes or iterations. It navigates the environment thousands of times, familiarizing itself with the dynamics and outcomes of different actions. The agent records which actions in specific states yield the highest rewards, progressively improving its decision-making process.
Now that we’ve covered the basics of how an agent interacts with its environment, the next step is to try to optimize these interactions. There are two key components to this process: learning and exploration. Just as caretakers guide a child, we need to teach our agent the best ways to learn and explore its given environment.
Policies in Reinforcement Learning
Just as parents provide guidelines and rules to help a child make decisions, a policy in reinforcement learning (RL) serves as the agent’s guide for choosing actions in different states. The policy is the core of the agent’s behavior and can be classified into two main types:
- Deterministic Policy: This type of policy maps a state to a specific action. Every time our agent reaches a certain state, it will take a certain action and only that action every time our agent finds itself in that state. It’s like giving a child a clear, strict rule to follow in a specific situation that they cannot deviate from.
- Stochastic Policy: This type of policy defines a probability distribution over actions for a given state. The agent chooses the next option based on the distribution of probabilities that we provide it. It’s similar to letting the child make their own decision based on the choices we give them and how likely they think they are to receive a reward for their choice.

In practice, policies can be simple rule-based systems or complex neural networks that adapt over time as the agent learns. The chosen policy directly influences the agent’s behavior and, consequently, its success in achieving goals.
The rules that we set for the children have a bigger purpose to it. For example, we might set a (deterministic) rule for them to go to sleep at 10pm so they can become early birds when they grow up. This bigger purpose is what is called learning strategy.
Learning Strategies in Reinforcement Learning
Once we have defined a policy, the next step is to optimize it through learning strategies. Our RL agent requires appropriate learning strategies to refine its policy. These strategies determine how the agent updates its policy based on interactions with the environment.
When learning something new, we often create a roadmap to guide our learning journey, review various resources, establish milestones, and reflect on progress. These steps help us optimize our learning experience and apply new skills effectively. Similarly, we need to employ the appropriate learning strategy for our agent to enhance its performance in a particular environment. Here are the main types of learning strategies:
- Value-Based Methods: These methods, such as Q-learning, focus on estimating the value of actions or states. They update the policy based on the expected reward of actions, refining the agent’s behavior incrementally.
- Policy-Based Methods: These methods directly optimize the policy without using value functions. Techniques like REINFORCE and Actor-Critic fall under this category. They adjust the policy parameters to maximize the expected reward.
- Model-Based Methods: These methods involve learning a model of the environment’s dynamics. The agent uses this model to predict outcomes and plan actions. Model-based methods can be more efficient but require accurate modeling of the environment.
Popular Examples of Learning Strategies:
(Both fall under Value-based Methods)
- Monte Carlo Methods: These methods learn from complete episodes of experience. This means that the agent learns from its mistakes after the milestone is reached instead of at every move it makes. More technically, the agent collects data over an episode, then updates its policy based on the total reward received. After the episode it reassess its strategy to analyze the entire sequence of moves to determine which were successful and which weren’t. While this approach provides a comprehensive understanding, it can be time-consuming and resource-intensive.
- Temporal Difference (TD) Learning: TD methods, like Q-learning, update the policy at each step, using the difference between predicted rewards and actual rewards. TD methods use bootstrapping, which means they update value estimates based on other current estimates rather than waiting for the final outcome. With TD learning, you’d analyze each move as you, the agent in this case, play. After making a move, you immediately assess its impact at the current state, updating your strategy in real-time. This method allows for continuous learning throughout the game, making it more efficient and adaptable to changing circumstances.

When choosing between Monte Carlo and TD methods, consider the nature of the task at hand. Monte Carlo is ideal for scenarios with clear start and end points, where complete episodes of experience are available. On the other hand, TD learning shines in dynamic environments where feedback is received incrementally, allowing for rapid adjustments and fine-tuning of strategies.
Exploration Strategies
After choosing a learning strategy, the next step is deciding how the agent should interact with and explore its environment. Exploration is key to discovering optimal policies. The trade-off between exploration (trying new actions) and exploitation (using known actions) is crucial to understand for RL.
Exploration-Exploitation Trade-Off:
When you visit a new restaurant or café, you often want to explore as many new items on the menu as possible. This helps you try new things and discover what suits your taste buds best. However, as you become a regular, you tend to explore less and stick to what you’ve enjoyed in the past. In RL terms, the first few visits involve more exploration, while later visits focus on exploiting the most rewarding options.
This is the essence of the exploration-exploitation trade-off. When you explore, you sacrifice the opportunity to exploit, and vice versa. Both exploration and exploitation are crucial for training our agent. This trade-off helps our agent balance the need to explore new actions to discover their potential rewards against exploiting the best-known actions to maximize immediate rewards. Effective RL models must strike a balance between these two aspects to learn optimal strategies.

Common Exploration Strategies:
- Epsilon/ε-greedy: Continuing with our example, at a restaurant or café, most of the time, you stick to your favorite dish because you know you enjoy it. However, occasionally, you decide to try something new to explore other options. This is similar to the ε-greedy strategy in reinforcement learning. With probability ε, the agent explores randomly; otherwise, it exploits the best-known action. This simple strategy ensures that the agent continues to explore the environment, albeit at the cost of occasionally making suboptimal choices.
- Softmax: Continuing with our example at a restaurant or café, imagine you’re deciding which dish to order based on their estimated deliciousness. With the softmax strategy, you probabilistically choose dishes, assigning higher probabilities to those with higher ratings on their reviews. This method allows you to allocate more of your budget to the dishes you believe will be the most satisfying, while still leaving room to experiment with other options based on their perceived appeal. In RL terms, the softmax strategy ensures that actions are chosen based on their estimated value, with higher probabilities assigned to actions with higher expected rewards. This approach strikes a balance between exploiting the best-known actions and exploring other options to optimize overall performance.
Exploration ensures that the agent doesn’t get stuck in suboptimal behavior and can discover better strategies.
Reward Function
Designing rewards in reinforcement learning is akin to crafting a system of incentives for children to encourage desirable behavior. Just as a parent might use praise, treats, or extra playtime to reinforce good habits, in RL, we design reward functions to guide the agent towards optimal behavior. These rewards must be carefully balanced to ensure they effectively promote the desired outcomes without introducing bias or unintended consequences. For example, if we want our agent to learn to navigate a maze, we might reward it for reaching the end but also provide smaller rewards for making progress toward the goal. Thoughtfully designed rewards help the agent understand which actions are beneficial and should be repeated, ultimately shaping its behavior and learning process to achieve the specified objectives efficiently.

Bringing it All Together — How to Design Your RL Model
Designing an RL model is akin to nurturing a child’s learning journey and helping them reach their full potential. Here’s how you can guide your agent, much like a caring parent:
- Define the Problem: Just as you’d understand your child’s environment and goals from your experiences, identify the environment, states, actions, and objectives in your agent’s RL scenario.
- Choosing Appropriate Learning Strategies: Like deciding on the best approach to teach your child, select the appropriate policy and learning strategy.
- Determine Exploration Strategy: Similar to encouraging your child to explore their interests, choose exploration techniques that balance learning efficiency. Consider strategies like ε-greedy or softmax to help your agent explore new possibilities while leveraging known successes.
- Design the Reward Function: Craft rewards thoughtfully, just as you would praise or reward your child for positive behavior. Ensure the reward function guides the agent toward desired outcomes without introducing bias or unintended behaviors.
By combining these elements thoughtfully, you can create effective RL models that learn and adapt efficiently.
Conclusion
Reinforcement Learning is a powerful tool for training agents to make decisions. Understanding the different aspects, from learning strategies to exploration techniques, is crucial for designing effective RL models. By grasping these concepts, beginners can start experimenting with RL and build models that tackle complex problems.
I hope this was helpful! I am hoping to write another article that discusses these topics more technically, so stay tuned :)