6 Step Optimization of GeMMs in CUDA
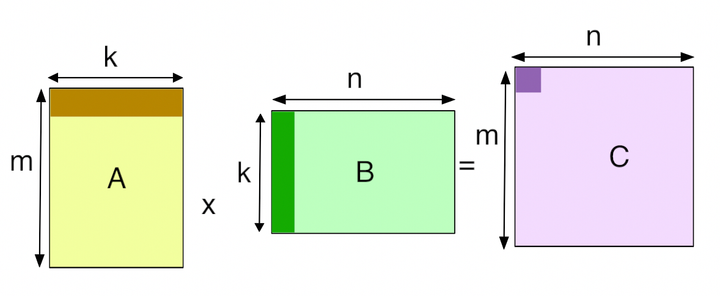
I aim to take a naive implementation of single-precision (FP32) General Matrix Multiplication (GeMM) and optimize it so its computations can be parallelized effectively on GPUs with CUDA C/C++.

Learning new technical concepts through coding, analyzing, and research papers.